Academic data publishing is the biggest ROI in research today
A decade of running Figshare says the big win was simply getting data onto the internet. The next ten years are about making it usable.

After a decade of running Figshare (a data publishing repository), I think the biggest cultural, and impactful change of the last 10 years to be ‘encouraging researchers to put data on the internet’. ROI = Return on Investment. With steady behavioural change, I think the next 10 years are all about making that data useful for machines. This gives funders and academia the lowest risk:reward ratio for a next paradigm in research. This is how we move further, faster.
We will naturally get to better transparency and reproducibility in research by making data openly available, linked from peer reviewed publications. However, to create a real step-change in discovery of new knowledge, research needs to take advantage of artificial intelligence acting upon large swathes of reproducible research data with homogenous metadata. Alphafold from Deepmind was the first example of how monumentally powerful this combination can be in 2020.
“AlphaFold is a once in a generation advance, predicting protein structures with incredible speed and precision. This leap forward demonstrates how computational methods are poised to transform research in biology and hold much promise for accelerating the drug discovery process.”
Arthur D. Levinson, PhD, Founder and CEO Calico, Former Chairman and CEO Genentech.
Helping guide the world on areas to focus are the United Nations Sustainable Development Goals (SDGs). At its heart the 17 SDGs are an urgent call for action by all countries – developed and developing – in a global partnership. They recognize that ending poverty and other deprivations must go hand-in-hand with strategies that improve health and education, reduce inequality, and spur economic growth – all while tackling climate change and working to preserve our oceans and forests. Creative Commons is one of the more interesting recent participants in attempting to solve this. They recently received funding for a four-year, $4 Million Open Climate Campaign to open knowledge to Solve Challenges in Climate and Biodiversity in collaboration with SPARC.
Similarly, on 23 November 2021, UNESCO’s Recommendation on Open Science was adopted by 193 Member States during the 41st session of the Organization’s General Conference.
“This Recommendation outlines a common definition, shared values, principles and standards for open science at the international level and proposes a set of actions conducive to a fair and equitable operationalization of open science for all at the individual, institutional, national, regional and international levels.”
Recognizing the urgency of addressing complex and interconnected environmental, social and economic challenges for the people and the planet, including poverty, health issues, access to education, rising inequalities and disparities of opportunity, increasing science, technology and innovation gaps, natural resource depletion, loss of biodiversity, land degradation, climate change, natural and human-made disasters, spiralling conflicts and related humanitarian crises,
In North America, Federal agencies are celebrating 2023 as a Year of Open Science, a multi-agency initiative across the federal government to spark change and inspire open science engagement through events and activities that will advance adoption of open, equitable, and secure science. This has already seen commitments from NASA, NIH, NEH and 5 other agencies, as documented on the new open.science.gov page. This all sounds great – so what can we do to help move things further, faster?
How do we as a society find areas to focus on?
With generalist repositories, there is now a home for every dataset – no matter the research field, or funding situation. However, we also know that subject specific repositories can provide subject specific guidance around metadata schemas and ways to make the files they generate useful. Re3data lists 2316 disciplinary repositories globally. Whilst this is encouraging, this self-reporting database also contains a few redundant repositories. Sustainability models for generalist repositories appear to be an easier problem to solve than subject specific repositories. We also now have the tools to identify what research areas are lacking in tools to help define subject specific metadata standards, in an actionable way.
Using Dimensions.ai, we can look at SDG categorisation of all datasets catalogued by DataCite. This provides a great snapshot of which SDG has good coverage when it comes to data publishing. To normalise these counts, we can look at the patterns for traditional published research papers. The graphs below highlight a similar pattern across papers and data. Health, climate, and energy dominate. This seems in line with the most urgent of the SDGs, however, by definition, they are all urgent – and subsequently we see there is not enough research being funded for issues like poverty, clean water, and gender equality.
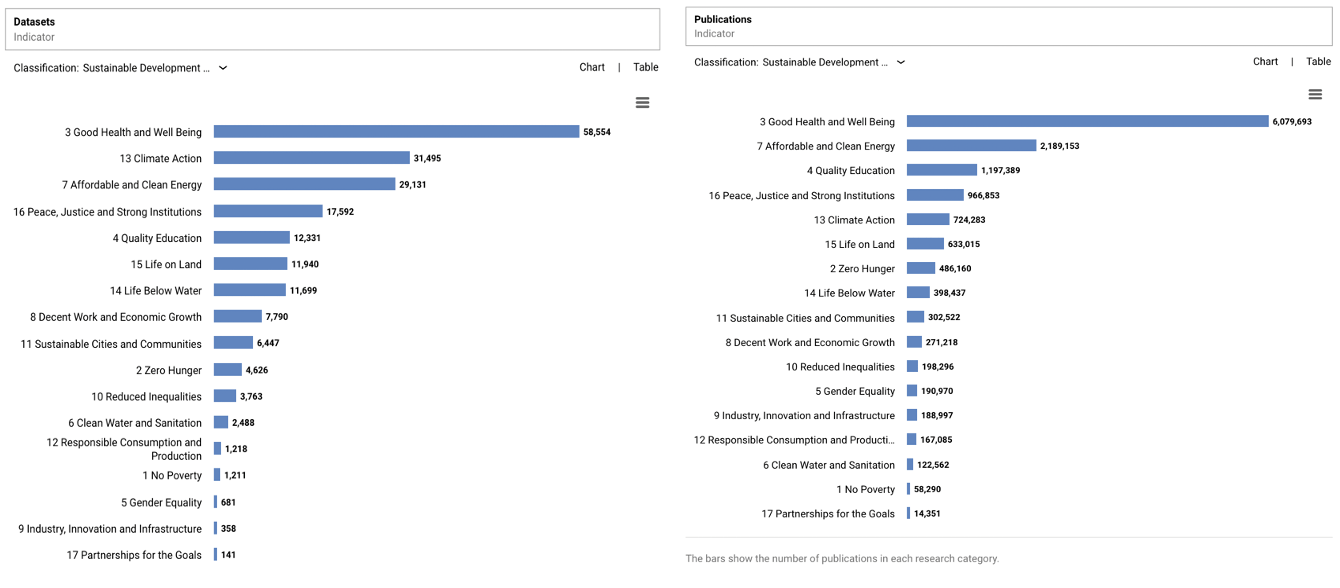
Digging deeper into the Dimensions dataset, we also see how generalist repositories, whilst providing a way for all researchers to publish datasets, may also be leading researchers to a “path of least resistance”. For example, Zenodo has more datasets that can be categorised as useful for the SDG of “climate action” than the World Data Centre for Climate. I am sure that my colleagues at Zenodo would prefer that these datasets ended up in a subject specific repository that is one layer closer to being interoperable and reusable than generalist repositories, such as Figshare and Zenodo.
As generalist repositories, our responsibility is to ensure that the platforms we build can support FAIR (Findable, Accessible, Interoperable and Re-usable) data. We know that the I and R of FAIR require more curation. The solution we have for this is humans. Librarians and data curators who can facilitate making research data and associated metadata as rich as possible. As a result – Institutional data repositories are often a level above generalist repositories as they can offer a layer of said curation. Our “State of Open Data” report highlighted that when researchers need to publish their data, the academic publisher is their first port of call. As such, there is a huge opportunity for publishers and societies to define metadata schemas at the subject level.
When it comes to repositories, academia and all subsequent stakeholders should:
- As a collective, agree on and start using consistent thematic metadata
- Improve metadata quality using computers or human curation
I think the next 10 years are all about making that data useful for machines. This is how we do it. In the last 10 years, I have learned to understand the power of incentives in academia. At times I feel we are trying to trick researchers into doing the right thing. When it comes to the integrity of research, we must hold researchers accountable. When it comes to understanding why researchers sometimes need perverse incentives to be a good researcher, we need to look at ways to improve the dog-eat-dog pyramid scheme that academia can become. Culture change takes time. However, researcher adoption of data publishing is happening at a fast rate. We should and will continue to champion this action and those who lean into it. Data publishing is the biggest ROI in research today. It is truly an agent of change and I for one am excited that we have made it this far. Now funders have mandated data publishing writ large, I am also excited for the road ahead.