Academic Research Data. Is it being cited?
Daily citation updates across Figshare show which research outputs actually attract citations, and why datasets still trail papers badly.

Recently, we partnered with our sister company Dimensions to offer daily citations updates on any object within any Figshare instance.
Our State of Open Data report that comes out each year has consistently highlighted that increased impact and visibility is the number one driver (78% on respondents value data citations as much or more than a paper citation) are the number one driver in motivating researchers to publish their datasets and the accompanying files their research generates.
This also allows us to begin to investigate patterns in the citation data that may help us understand the motivations of researchers to reuse content both generally and in specific fields. Data citations still struggle to find their way into reference lists, instead being cited inline within the article itself or in data availability statements. As such, we have partnered with our sister company Dimensions to identify these citations in the full text of articles. This ensures that researchers, and our clients, are aware of all of the citations to their research.
To start our investigations, we looked at the top 100 cited outputs on figshare.com, the the public data repository that is free for researchers to upload research to. In the future, it may also be interesting to compare rates of citation between institutional outputs that have been curated or checked, and those which have not.
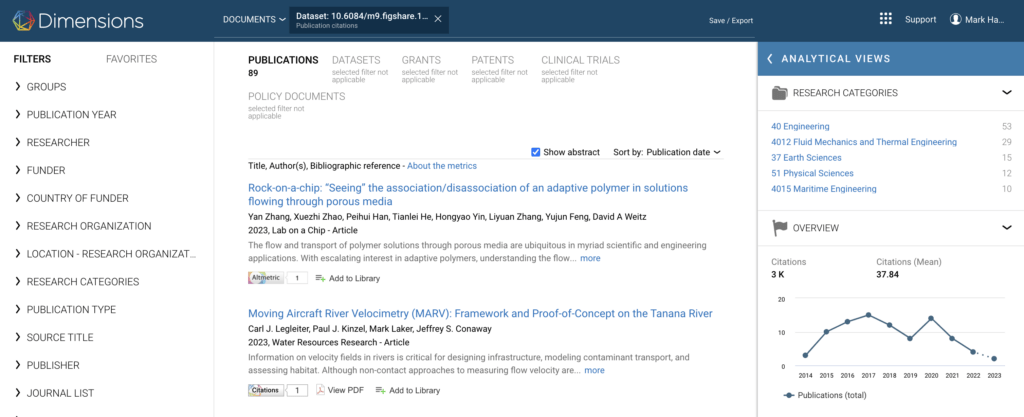
There is a long tail of outputs with 1 citation, which we can assume to be a citation of the output in the original paper describing the work by the same authors. Similarly, we can infer that outputs with more than 1 citation, cited in publication(s) by different authors, have been reused. Here are some other interesting preliminary findings.
4 out of the top 10 are software with a mean citation count of 50.5!
The code repositories have a few things in common.
- Each has a README file
- Each has multiple versions
- Each has lots of metadata associated with it. Sometimes this description is includeddirectly on the landing page, as is the case with PIVlab – Time-Resolved Digital Particle Image Velocimetry Tool for MATLAB (https://doi.org/10.6084/m9.figshare.1092508). For others, we find context to the work on other sites that link directly to the output, which are picked up by the Altmetric Explorer tool. Whether it be a Wikipedia article describing the software, as is the case for Common Workflow Language, v1.0 ( https://doi.org/10.6084/m9.figshare.3115156.v2) or blog posts that describe the The graph-tool python library (https://doi.org/10.6084/m9.figshare.1164194.v14) or PyMKS: Materials Knowledge System in Python (https://doi.org/10.6084/m9.figshare.1015761.v2)
Interestingly, there are 12 outputs labelled by authors as software in the top 100, despite software making up just 1.6% of outputs on figshare.com. This suggests that software can be highly reused and the impact it is having is not being captured in traditional credit mechanisms.
32 out of the top 100 are datasets
As of today, outputs labelled by authors as datasets make up 30% of outputs on Figshare.com. Therefore, finding that 32% of the top 100 cited outputs are datasets seems logical.
Obviously with the many different types of outputs that researchers want credit for, there are some that lend themselves to reuse and traditional citation metrics better than others. Notably, posters and presentations rarely get cited. But this does not mean that it isn’t happening. There is 1 presentation and 2 posters in the 100 most cited outputs.
The author of said presentation has picked up multiple citations over multiple different outputs, suggesting that the credibility of the author and their work is a key factor in driving impact.
Soon Figshare’s newly launched faceted search functionality will also include the ability to filter search results by citation count and Altmetric score in any Figshare portal. We’re excited about the new ways to encourage researchers to share all of their research outputs and make sure they get credit for the work. We look forward to continuing to investigate patterns of data reuse and working with the community on methods to make all the products of research more reusable.