All of the knowledge for all of the machines
By processing and analysing vast amounts of scholarly work, AI will enable breakthroughs in research, innovation, and problem-solving across numerous disciplines. But what can be legally accessed and what can be trusted?

All peer-reviewed articles available to all, and to AI? Inevitable, Illegal?
There are two slow revolutions happening in academic publishing:
- Blurring the lines between publishing peer-reviewed and non-peer-reviewed content
- Moving to a world where every paper is published Open Access
Does this lead to complications when applying machine-learning models to the research literature? By processing and analysing vast amounts of scholarly work, AI will enable breakthroughs in research, innovation, and problem-solving across numerous disciplines. It will possess an unparalleled ability to identify patterns, synthesise information, and generate novel insights that could lead to transformative discoveries. But what can be legally accessed and what can be trusted?
Blurring the lines between publishing peer-reviewed and non-peer-reviewed content
The preprint revolution kicked off in Physics in 1991 with arXiv by Paul Ginsparg. arXiv is internationally acknowledged as a pioneering and successful digital archive and open-access distribution service for research articles, pre peer review. Preprints had a big resurgence in the last 5 years as the desire for faster publishing of research took hold. Notably, biorxiv seems to be doing for Biology, what arXiv has achieved in the Physics world.
The logic for immediate publishing of research is probably best summed up by the eLife team
- Authors should be able to share their work freely and openly when they think it is ready.
- Peer review should consist of scientists publicly sharing their assessments of already published papers, either under the auspices of an editorial organization that oversees the review process, or on their own.
- Works of science should be reviewed by multiple relevant groups and individuals throughout their useful lifespan.
They have taken a huge leap in reviewing their model of publication and becoming a hybrid pre- and post- peer review publishing house.
we will publish every paper we send out for review as a Reviewed Preprint, a journal-style paper containing the authors’ manuscript, the eLife assessment, and the individual public peer reviews.
This is pretty much a professionalised version of Stevan Harnard’s Subversive Proposal, which is now nearly 30 years old:
If all scholars’ preprints were universally available to all scholars by anonymous ftp (and gopher, and World-wide web, and the search/retrieval wonders of the future), NO scholar would ever consent to WITHDRAW that preprint from the public eye after the refereed version was accepted for paper “PUBLICation.” Instead, everyone would, quite naturally, substitute the refereed, published reprint for the unrefereed preprint.
But this does beg the question, should large language models (LLMs) be taking in un-peer reviewed content to generate new knowledge? If not, how do we ensure it is filtered out.
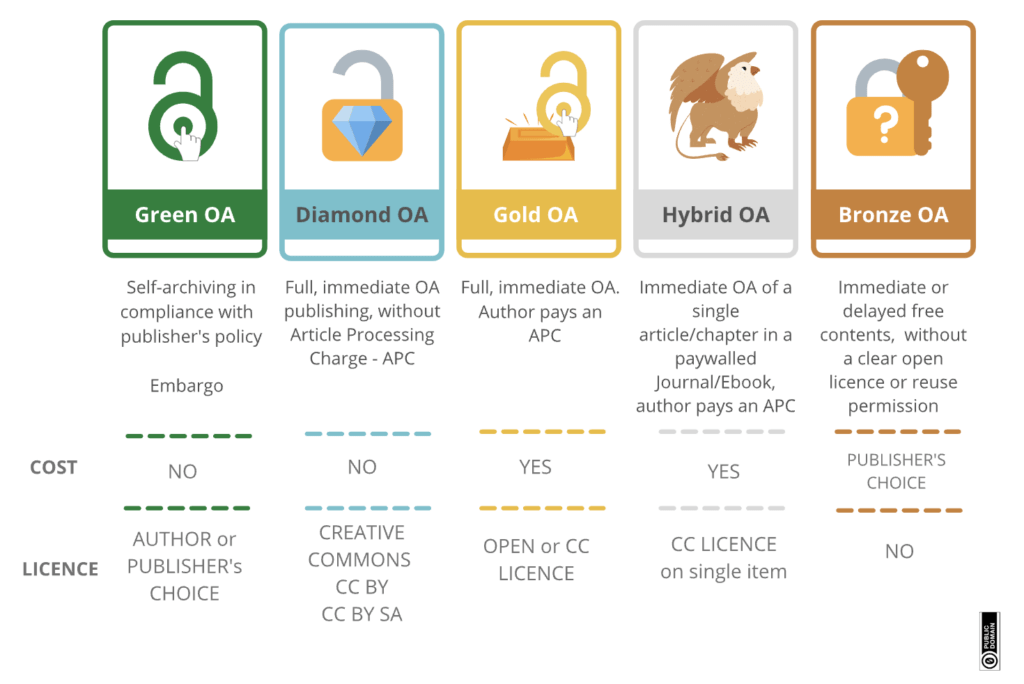
Moving to a world where every paper is published Open Access
There are similar grey areas in the world of open access. In 2002, a meeting of scholars and activists took place in Budapest, Hungary, leading to the formulation of the Budapest Open Access Initiative (BOAI). BOAI defined open access as free availability on the internet, permitting any user to read, download, copy, distribute, print, search, or link to the full texts of these articles. We suggest that this is true for both humans and machines. The green open access route often results in papers that can be similar, but not exactly the same as the closed access version. However due to actions by funders around the world, we have passed 50% of papers being Open Access in some way, each year. [This is further compounded by the release of the OSTP Memo from the Whitehouse](Update their public access policies as soon as possible, and no later than December 31st, 2025, to make publications and their supporting data resulting from federally funded research publicly accessible without an embargo on their free and public release;) which dictates that Federal Agencies should:
Update their public access policies as soon as possible, and no later than December 31st, 2025, to make publications and their supporting data resulting from federally funded research publicly accessible without an embargo on their free and public release;
The new disruptive models highlighted here create a ‘before and after’ feel to academic publishing. Every paper will be open and available to humans and machines alike. But what about the millions of papers still paywalled. They cannot be forgotten.
The decentralised web and p2p workflows have led to paywalled content becoming open on the web. Most notably, Sci-hub. However, no new papers have been added for 2 years, due to a pending Indian court case. This hasn’t stopped Alexandra Elkaban from winning the EFF Pioneer Award, or slowed the huge amount of usage that Sci-hub maintains. It is not hard to find torrents of this content, or new platforms taking advantage of decentralised infrastructure like ‘The InterPlanetary File System’ (IPFS). IPFS is a protocol, hypermedia and file sharing peer-to-peer network for storing and sharing data in a distributed file system. Recent incumbents include Standard Template Construct, Nexus Telegram bots and Science Hub Mutual Aid. If I can access this content via google, bots and machines would no doubt assume to do the same.
The collective intelligence stored within the world’s peer-reviewed academic literature will empower AI to propel human progress by accelerating scientific discovery and fostering a deeper understanding of the world around us. If this is not a legal approach today, the academic world needs to create easy ways to AI-mine legally accessible full-text articles.