Preprints.ai: How Much of Peer Review Can We Automate?
What problem are we trying to solve?
Peer review is structurally failing. The volume of preprint submissions has grown faster than the reviewer pool for decades. Average review turnaround times have lengthened. Reviewer fatigue is well-documented. And review quality is inconsistent in ways that are impossible to fix when the process depends entirely on the goodwill of overcommitted academics. More simply, can we score every preprint.
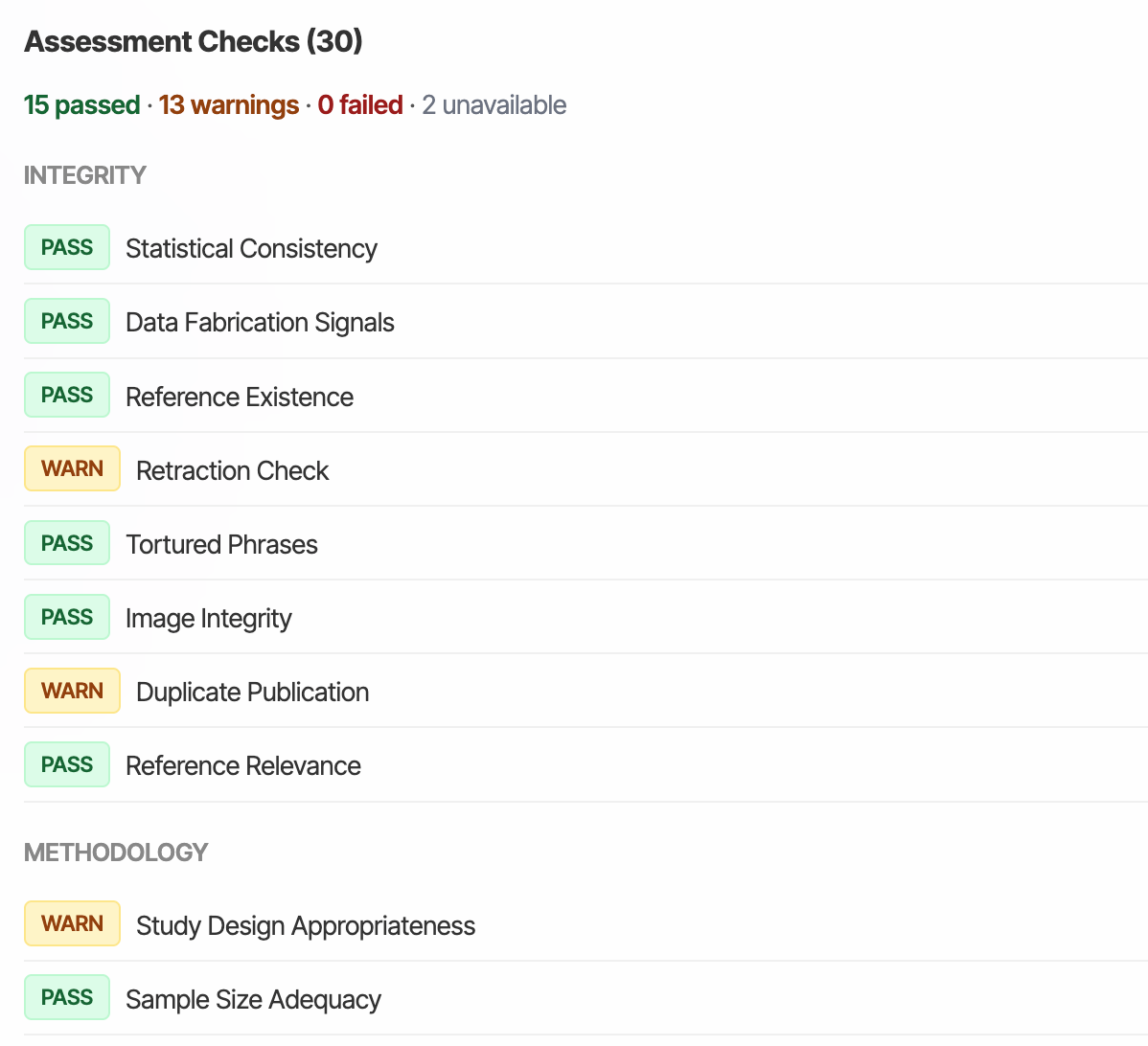
At the same time, a significant fraction of what peer reviewers actually do is mechanical. Checking that statistical methods match reported results. Verifying that cited claims are accurately represented. Assessing whether the methodology section contains enough detail to reproduce the experiments. Scanning for common red flags - tortured phrases from paper mills, image duplication, impossible p-values.
Preprints.ai asks a sharper question than "can AI help with peer review?" It asks “if we were designing peer review from scratch for a world where powerful LLMs exist, what would we actually need humans for, and what could we comfortably automate?”
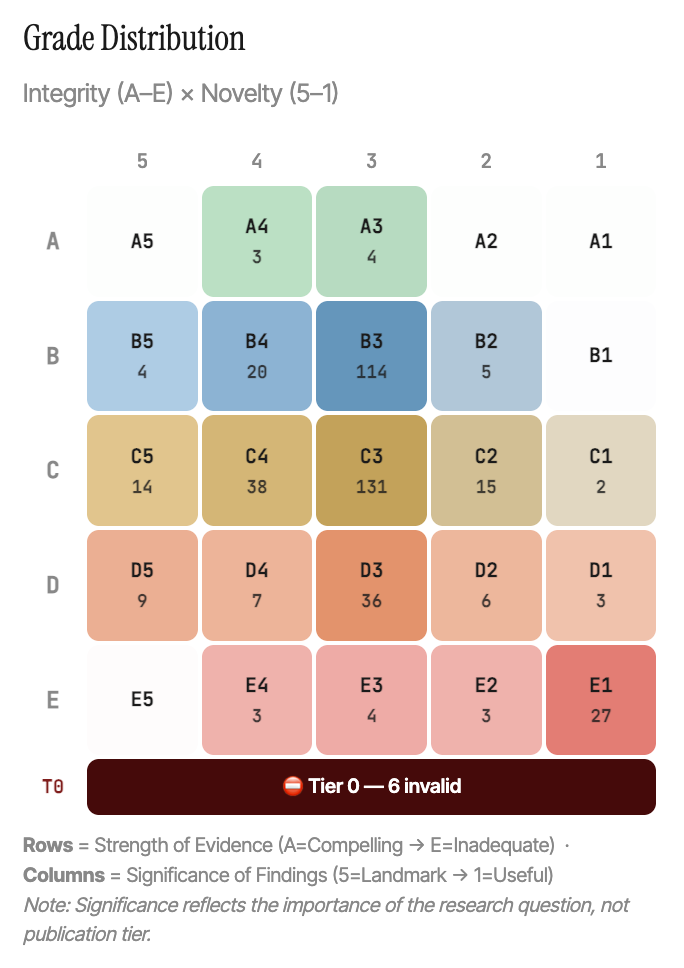
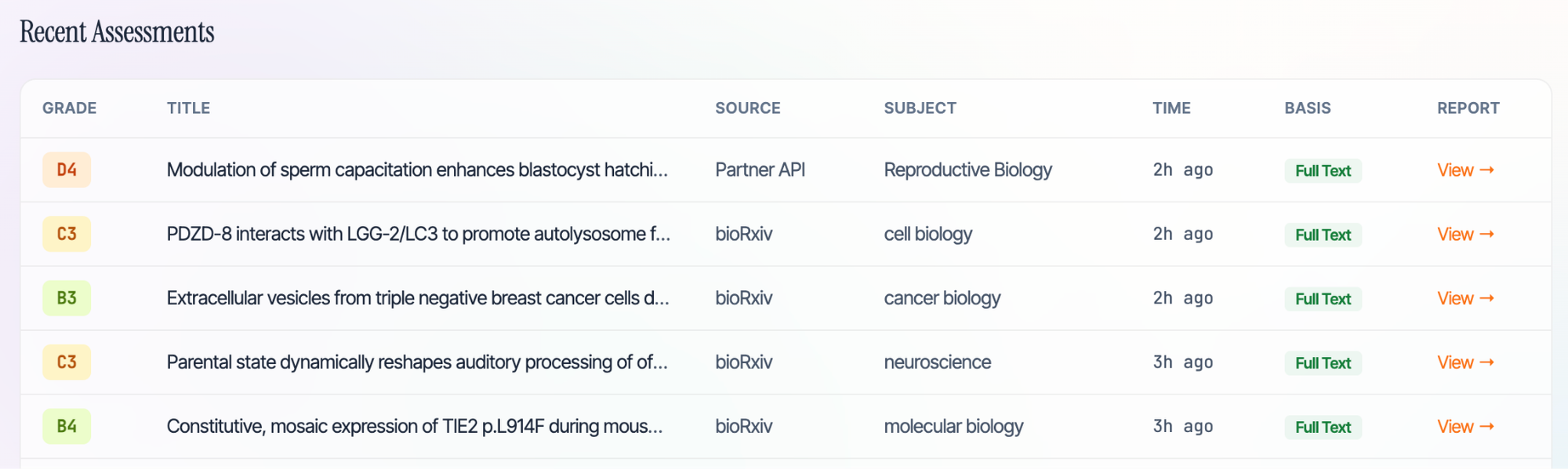
The platform currently runs a multi-agent review pipeline against preprints from bioRxiv and medRxiv, assessing two dimensions: research integrity (methodology, statistical validity, reproducibility, citation accuracy) and novelty (does the core claim already exist in the literature?). The output is a structured assessment graded on an A5-to-E1 rubric, with positivity bias actively recalibrated using publication outcome data.
What tools have inspired or been used to build this platform?
LLM providers and hybrid routing
We use three LLM providers in production, with each agent in the review panel assigned to a different provider to ensure genuine inter-model independence:
This isn't just cost optimisation. When three different model families independently agree on a finding, the probability that all three share the same hallucination is substantially lower than any single model's error rate. Round-robin provider assignment prevents correlated model bias in the consensus score.
The review pipeline: Layer 1 (deterministic, zero LLM cost)
Before any LLM sees the paper, a battery of rule-based checks runs in under 2 seconds:
PDF Quality Gate → Language Detection → Paper Mill Detection → Image Forensics → Statistical Consistency → Trust Markers
These are inspired by and build on established tools - such as Ripeta’s Trust Indicators.
- Paper mill detection uses a database of 8,000+ tortured phrases (e.g., "bosom malignancy" for "breast cancer") and 257 SCIgen patterns for computer-generated text
- Statistical consistency implements the GRIM test (Granularity-Related Inconsistency of Means) and statcheck-style p-value recalculation from reported test statistics
- Image forensics is inspired by ELIS (Error Level Image Similarity) — detecting duplicate figure regions, inconsistent compression, and manipulation artefacts using imagehash and Pillow
- Fabrication detection checks for Benford's Law deviation in reported data and suspiciously perfect statistical distributions
- Trust markers detect the presence (or absence) of data availability statements, code repositories, ethics approvals with protocol numbers, pre-registration links (ClinicalTrials.gov, OSF), ORCID identifiers, and CRediT author contributions
- Reporting guideline compliance checks against ARRIVE (animal research), CONSORT (clinical trials), PRISMA (systematic reviews), and MIQE (qPCR)
The review pipeline: Layer 2 (multi-agent LLM review)
The agent architecture is heavily inspired by eLife's deliberative review model. We run nine specialist agents, each with a distinct role and scope boundary:
Plus three additional domain-specialist agents routed based on the paper's bioRxiv category, drawn from a pool of 31 field-specific configurations covering everything from biochemistry to systems biology. Each configuration specifies methodology standards, common issues, reporting guidelines, statistical expectations, and key databases for that field.
Deliberation: from independent reviews to consensus
Independent review is necessary but not sufficient. In human peer review, the reviewing editor synthesises reviewer comments into a coherent assessment. We replicate this with a structured deliberation protocol inspired by eLife:
- Round 0 (Independent review) - All 9 agents review the paper in parallel, each with a different LLM provider. No agent sees any other agent's output.
- Round 1 (Consultation) - Agents see anonymised summaries of each other's reviews. Each can agree, challenge, or add nuance.
- Round 2 (Reconciliation) - A senior editor agent synthesises the consultation into a single eLife-style assessment: "This study presents [significance] findings on [topic]. The evidence is [strength], with [justification]."
- Dissent recording - Any agent that disagrees with the final assessment can lodge a recorded dissent, preserved in the output for transparency.
This substantially reduces variance compared to single-pass review. We track inter-agent agreement (standard deviation of scores across agents) and use it as a confidence signal. eg. high disagreement triggers lower confidence scores and flags the paper as borderline.
External data sources
The platform integrates with multiple academic data APIs, each serving a distinct purpose:
The scoring rubric
We grade on two independent dimensions, producing a combined grade like B4 or C3:
Integrity (A–E): Strength of evidence. A = compelling, reproducible methodology with full transparency. E = fundamental unfixable problems (fabrication signals, pseudoscience, paper mill indicators).
Novelty (5–1): Significance of findings. 5 = landmark, field-shifting (almost never assigned). 3 = important, real contribution beyond a single subfield. 1 = useful but very limited — one more data point.
Each grade maps to an editorial decision in journal-standard language: Accept, Minor Revision, Major Revision, or Reject — with modifiers for low confidence, abstract-only assessment, or high reviewer disagreement.
Fighting positivity bias using recalibration
LLMs are famously sycophantic. Left uncalibrated, every paper gets a B. We fight this at multiple levels:
- Downward recalibration rules: 2+ critical weaknesses forces a D floor. 4+ major weaknesses caps at low-C. A "reject" recommendation from any agent caps integrity at 0.42.
- Per-agent accuracy tracking: After each calibration run, we compute every agent's mean absolute error and bias against publication outcomes. Agents with measured bias > ±0.15 get a steering note injected into their next prompt: "Historical data shows you tend to overscore novelty by ~20%. Be especially critical of incremental contributions."
- Inverse MAE weighting: In the consensus aggregation, agents with lower historical error get higher weight. An agent that has been consistently accurate on past papers has more influence on the final score than one that hasn't.
- Publication outcome calibration: We match assessed preprints against publication records using Crossref’s open data. If we scored a paper as novelty-2 but it was published in a tier-5 journal, that delta feeds back into agent weights and prompt tuning.
Confidence and transparency
Every assessment includes:
- Confidence score (0–100%) derived from agent agreement, mean agent self-reported confidence, and score dispersion. High disagreement between agents lowers confidence.
- Individual agent reviews. Every agent's scores, strengths, weaknesses, and recommendations are available in the full report, not just the consensus.
- A 2–3 sentence plain-language summary of the core finding, for a non-specialist audience.
Cost per paper
With hybrid routing across Claude, GPT-4o, and Gemini Flash, the current cost per full assessment is approximately $1.50–2.00 for a consensus review with 9 agents. Layer 1 deterministic checks add negligible cost. At scale, with aggressive caching of reference verification results and local model routing for lower-signal checks, we expect this to converge toward $0.50–1.00 per paper.
What we can look to do next
Validation is the open question
The most important next step is systematic validation. How do Preprints.ai assessments compare to human peer review on the same papers? We've built a /validate page where domain experts can agree, disagree, or override AI grades but we need hundreds of expert validations across diverse fields before the calibration claims are defensible. There is no incentive for subject experts to do this, so we can assume they wont.
We're also running consistency tests. We are assessing the same papers multiple times to measure grade variance. If the system can't reproduce its own grades, nobody should trust them. Our target is >70% exact grade stability and >90% within-one accuracy.
Field-specific scoring norms
A C3 in clinical medicine means something different than a C3 in pure mathematics. We're computing per-discipline score distributions from assessed papers and using z-score normalisation to generate field-specific grade thresholds. Fields with sufficient data (20+ assessed papers) get their own norms; others fall back to global defaults.
The hybrid model question
Longer term, the interesting question is whether a hybrid model - AI as first-pass screen, human expert for borderline cases - could work operationally within a real journal workflow. The system already identifies which papers need human attention (low confidence, high agent disagreement, borderline C-range grades). The question is whether editors would trust it enough to act on.
I think the answer is yes, but only after the validation data proves it.If you're working on any of these problems and want to compare notes, or if you spot something obviously wrong with the approach, I'd be glad to hear from you.